Project overview
Collaboration is an integral part of human dialogue. Typical task-oriented dialogue games assign asymmetric roles to the participants, which limits their ability to elicit naturalistic role-taking in collaboration and its negotiation. We present a novel and simple online setup that favors balanced collaboration: a two-player 2D object placement game in which the players must negotiate the goal state themselves. We show empirically that human players exhibit a variety of role distributions, and that balanced collaboration improves task performance. We also present an LLM-based baseline agent which demonstrates that automatic playing of our game is an interesting challenge for artificial systems.
The website is currently being updated.
The Game
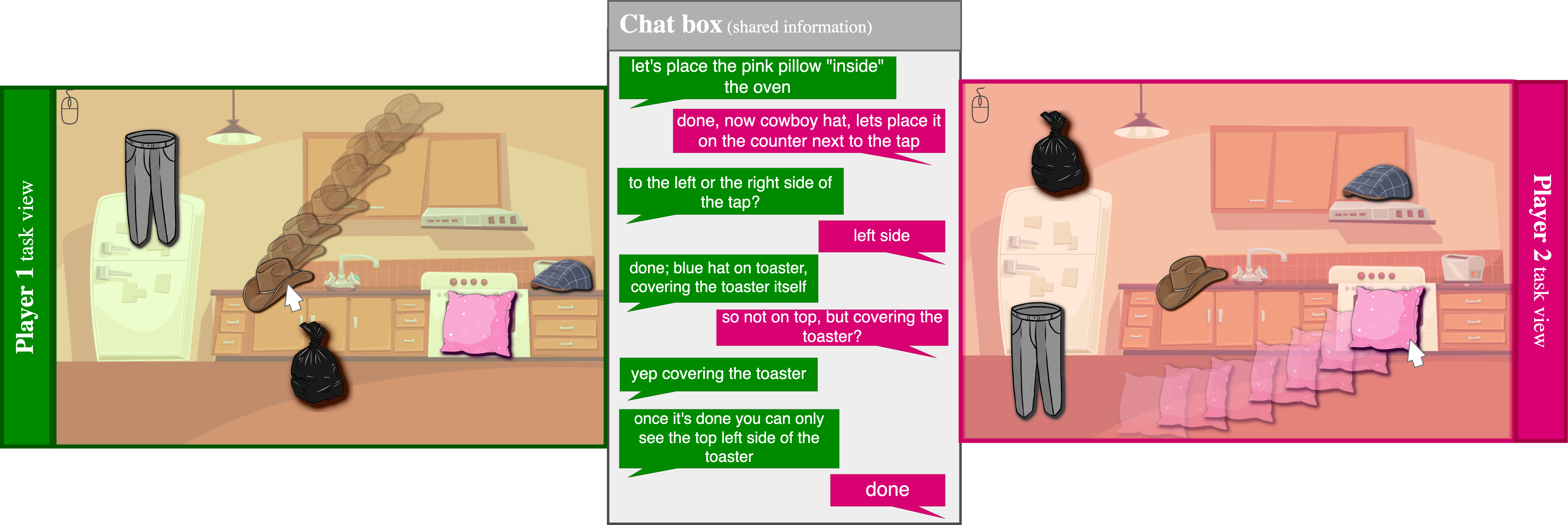
We developed a collaborative, 2D object placement game that can be played by two players over the Internet. In each round, the two players see an identical, static background, upon which movable objects have been placed in random positions that are different for the two players. The goal of the game is for the players to place each object in the same position by dragging it with the mouse. Players cannot see each other’s scene; they can only communicate through a chat window. Each pair played two rounds of the game together, allowing us to study how their collaboration strategies evolved with time and exposure.
Assets

Objects:

Player view
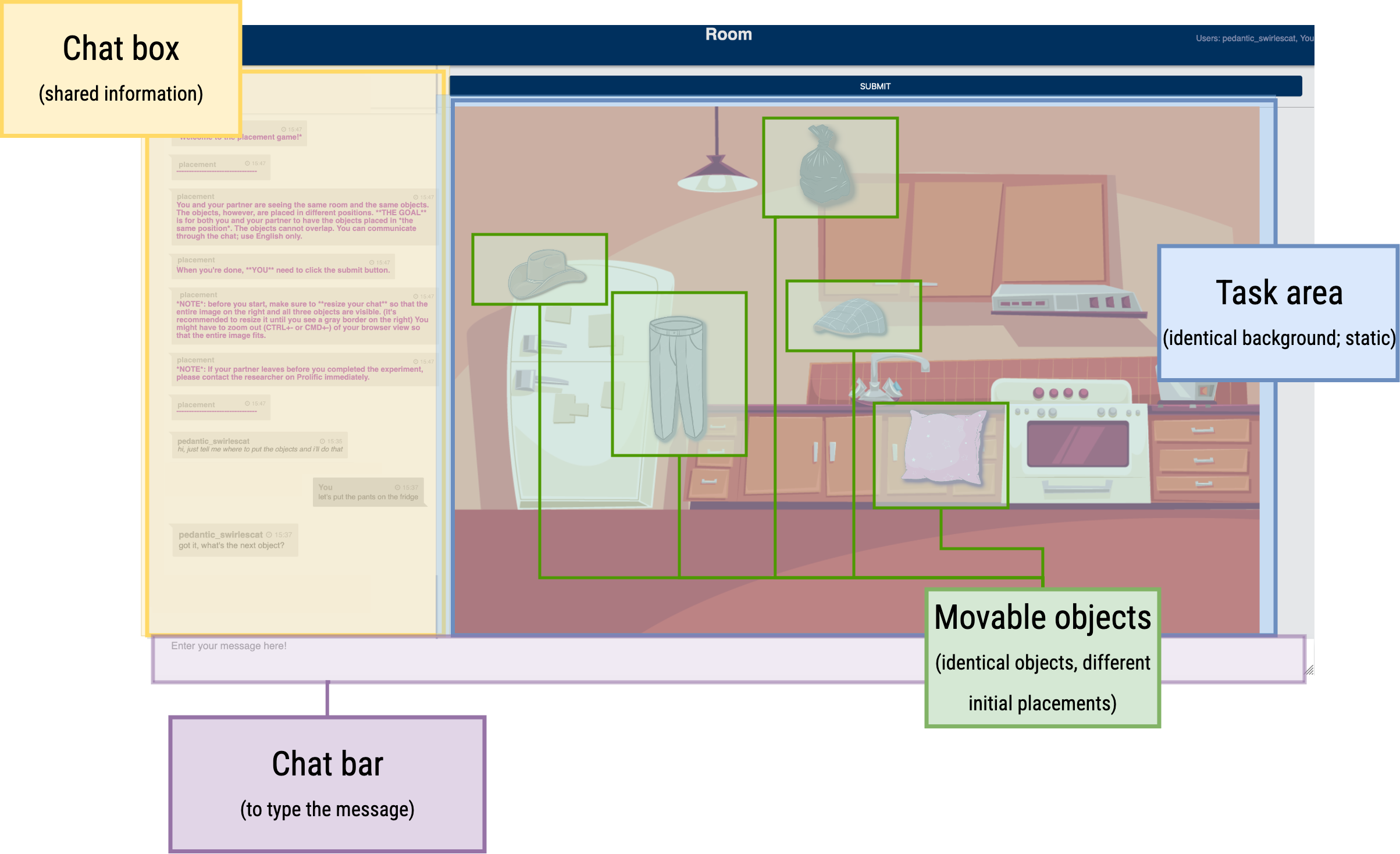
The game is deployed using Slurk (Shlangen et al., 2018; Götze et al., 2022), which provided an out-of-the-box frontend, including the separate chat box and stimulus areas, as well as an efficient customizable logging scheme.
Complete layout overview
The players are scored jointly based on the mean Manhattan distance (0 to 100) between identical objects - the closer the two common objects are placed, the higher the score the pair received.
Game-playing strategies
In order to analyze the dialogue, we collect human-human data from Prolific participants. We mannually observe different approaches to playing our game, as distinguished by qualitative linguistic features, such as which player is deciding on the conversation trajectory.
Specifically, we observe four distinct strategies:
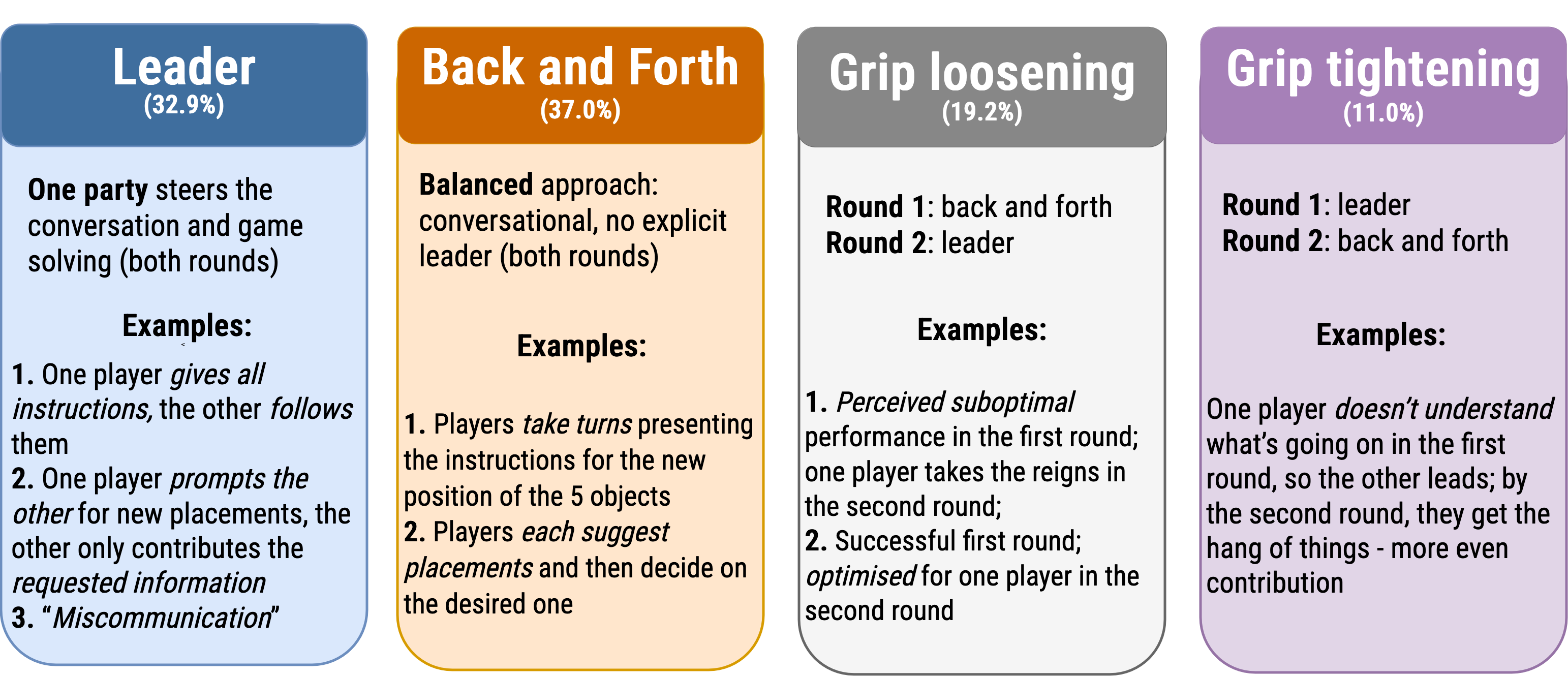
The brackets contain the percentage of total games employing each strategy.
Leader strategy example
TODOBack and forth example
TODOGrip loosening example
TODOGrip tightening example
TODOPerformance results
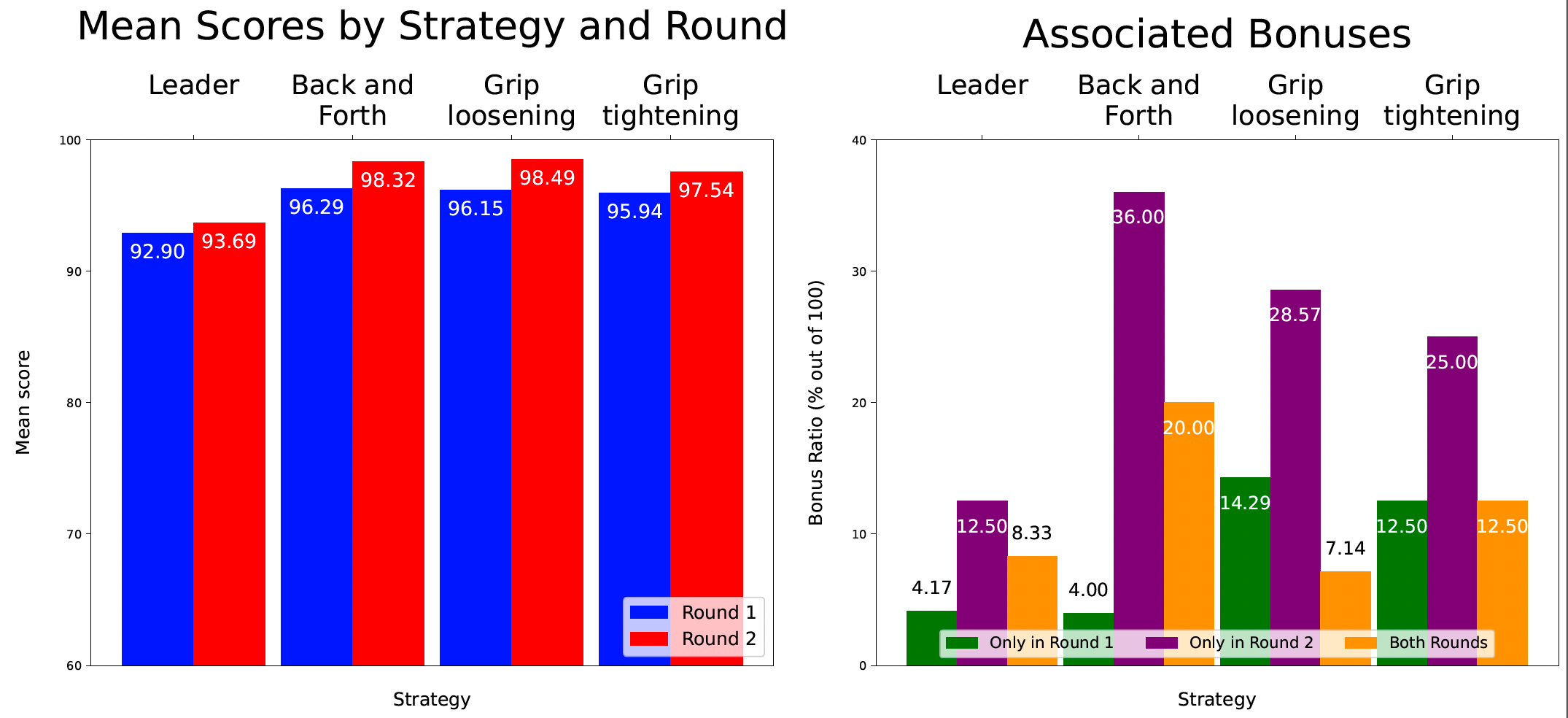
A figure breaking down game performance by strategy: left - mean scores in each round for the four collaboration strategies; right - proportion of games that received a bonus (score ≥ 99) in either and/or both rounds.*
When observing the results, it is clear that the Leader strategy consistently underperforms, with respect to the others - not only are its associated mean scores the lowest, but it has the smallest percentage of games with exceptionally high scores, i.e., fewest bonuses. This illustrates that our placement game is played most effectively by pairs who take a balanced approach to collaboration.
Dominance Score
Terminology:
For each player in each round of a game, we calculate a dominance score ( \(\mathcal{D}\) ) post-hoc, capturing how much one player dominates the way in which gameplay decisions are made. We assign a high dominance score to a player with high verbosity and high volume.
We calculate the verbosity and volume scores for each player and label them as A (higher volume) and B (the other). Then, we calculate the \(RD\) and use it, along with verbosity to obtain a final \(\mathcal{D}\).
(Note that RD is always positive.)
| Term | Equation | Description |
|---|---|---|
| verbosity | / | Mean message length per player. |
| volume | / | Percentage of messages sent by each player (0 to 100) |
| \(RD\) | \(\frac{\text{volume}_A - \text{volume}_B}{\text{volume}_A + \text{volume}_B}\) | Relative volume advantage of player A. |
| \(\mathcal{D}_A\) | \(\text{verbosity}_A \cdot L(RD)\) | Dominance for player A. |
| \(\mathcal{D}_B\) | \(\text{verbosity}_B \cdot (1 - L(RD))\) | Dominance score for player B. |
| \(L(x)\) | \(\frac{1}{1+e^{-x}}\) | Sigmoid function |
Example calculation
Example dialogue:
Here is a dialogue sample from a pair's second round. The labelling of players (P1, P2) is based on the first round, so here "P2" starts the round (reflecting on their previous round's score).| Player | Message |
| P2 | great |
| P1 | Pillow on couch right side |
| P1 | Maybe the rubbish bag under the table? |
| P2 | ok |
| P1 | The brown hat next to the pillow (centre of couch) |
| P2 | ok |
| P1 | Okay so my brown hat isn't moving |
| P2 | pillow on with couch? |
| P1 | Yes, the pillow on the double couch on the right side |
| P2 | Blue hat on the other couch |
| P1 | Do you have any objects that don't move? |
| P2 | the little one |
| P1 | Yes |
| P2 | pants where? |
| P2 | on top of the lamp? |
| P1 | Yes. But let's talk about the brown hat. My brown hat isn't moving |
| P1 | Brown hat on the centre of the mat |
| P2 | ok |
| P2 | done? |
| P1 | Yep |
| P2 | great |
Example values
| Player 1 value | Player 2 value | |
|---|---|---|
| number of messages sent | 10 | 11 |
| volume | 47.62 | 52.38 |
| verbosity | 7.5 | 2.36 |
| user label | B | A |
| \(RD\) | 0.048 | |
| \(L(x)\) | 0.488 | 0.512 |
| \(\mathcal{D}\) | 3.661 | 1.21 |
| \(\mathcal{D}_{difference}\) | 2.451 | |
Explanation and interpretation
In this example round, P1 sends fewer messages than P2 (10 vs. 11), which is reflected in their volume scores. However, P1's messages are longer than P2's (see verbosity). The overall dominance score for each player indicates that player 1 is more dominant, and their stark difference (2.451) indicates that their game would belong to the leader strategy.
Checking the qualitative analysis reveals that this is, indeed, the case, with this round being labelled as "leader" (where P1 gives most instructions, or prompts P2).
The strategies and their dominance scores
| Strategy | Round 1 | Round 2 |
|---|---|---|
| leader | 1.468 | 2.374 |
| back and forth | 1.17 | 0.981 |
| grip loosening | 1.421 | 0.988 |
| grip tightening | 0.884 | 1.696 |
The table to the side showcases the mean dominance score differences between the users averaged per round and grouped by strategy. We make the following observations:
- the leader strategy is characterized by highest values in both rounds, indicating the presence of an overtly dominant user.
- the back and forth strategy has a more balanced and smaller difference distribution in both rounds.
- In the case of the two mixed strategies, the R1 and R2 dominance score differences can be seen corresponding to their respective primary strategy counterpart:
- in the grip loosening case, R1 corresponds to R1 of the leader strategy, whereas its R2 corresponds to the R2 of the back and forth strategy.
- in the grip tightening case, R1 corresponds to the back and forth strategy, whereas R2 matches the leader strategy more closely.
LLM baseline agent
We build a hybrid reactive baseline agent that plays the game with a human player. The agent is forced into an instruction-follower role by sending the first message asking the human player for instructions.
Upon receiving a message, the system takes the following steps:
| Step | Description |
|---|---|
| Step 1 | verify if the message contains instructions |
| Step 2 | - parse the message - for each group (target, reference, direction): 1. extract them 2. map the term to one of the predefined allowed terms |
| Step 3 | change the position of the objects according to Step 2 based on predefined constraints |
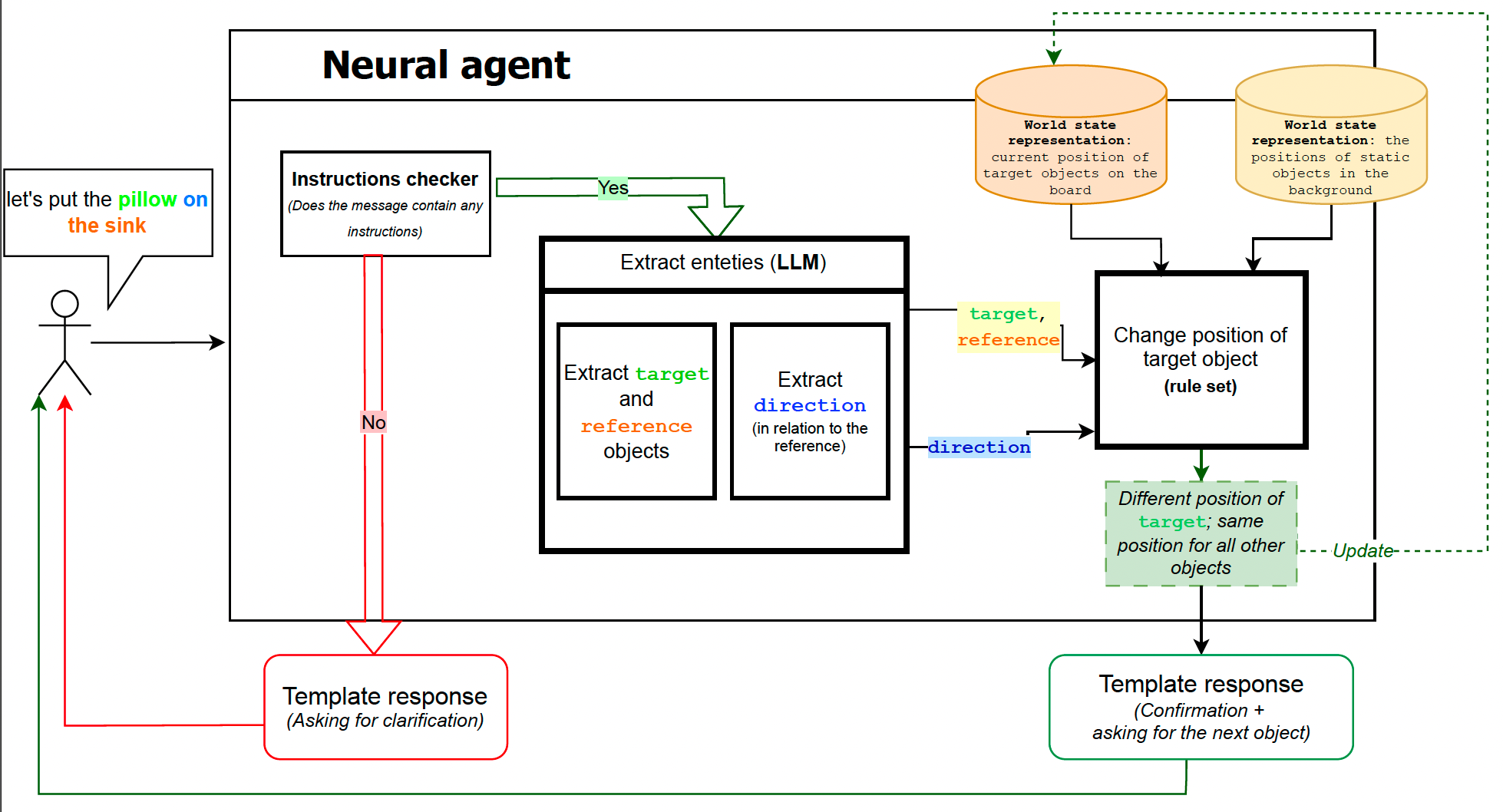 The architecture of the reactive baseline.
The architecture of the reactive baseline.
The steps in detail
Step 1 & 2
In order to complete these steps, we use LLMs with few shot learning.
The prompts we use are as follows:
Step 1 prompt (Checking if a message contains instructions)
You are playing a game with another player in which you have to follow their instructions about where to put certain objects. I will give you a message and I want you to tell me if it contains a set of instructions. Don't provide explanation, just give me the output (True or False). Examples: [user 1]: place the lamp on the fridge [you]: True [user 1]: can you put the knife in the drawer? [you]: True [user 1]: do you have a toaster? [you]: False [user 1]: what objects do you have? [you]: False [user 1']: let's place the pan on top of the lamp [you]: True [user 1]: put hat on sink [you]: True [user 1]: lamp on toilet [you]: True
Step 2 prompt #1 (Extracting and mapping the target and reference objects)
I will give you a set of instructions and I want you to extract two things: one, the object that should be moved. Then, I want you to compare it to the following four words and return the one it is most close to. The objects are: garbage, cowboy, cap, pants, pillow. Next, I want you to extract the location where the object should be placed. Then, match the output place with one of the possible places: fridge, counter, toaster, lamp, stove, oven, sink. Don't provide explanation, just give me the output. For example: [user 1]: put the pillow to the right of the fridge [you]: pillow, fridge [user 1]: put the jeans on the stove [you]: pants, stove [user 1]: let's place the cushion on the ceiling light [you]: pillow, lamp [user 1]: place the garbagebag in the upper right corner of the counter [you]: garbage, counter [user 1]: cowboy hat to the left of the water faucet [you]: cowboy, sink [user 1]: the other hat on the right behind the pants [you]: cap, toaster [user 1]: garbage bag on top of lamp stand [you]: garbage, lamp [user 1]: let's place the blue hat on the toaster [you]: cap, toaster [user 1]: put peaky blinders hat in the oven [you]: cap, oven
Step 2 prompt #2 (Extracting and mapping direction)
I will give you a set of instructions and I want you to extract the key spatial word or phrase. Then, I want you to compare it to the following four words and return the one it is most close to. The words are: above, below, next to, on. Don't provide explanation, just give me the output. For example: [user 1]: put the knife to the right of the fridge [you]: next to [user 1]: put the pan above the oven [you]: above [user 1]: place the toilet paper in the upper right corner of the cupboard [you]: on [user 1]: cowboy hat to the left of the water faucet [you]: next to [user 1]: the cowboy hat on the right behind the pants [you]: next to [user 1]: pillow under the sink [you]: below [user 1]: garbage bag on top of lamp stand [you]: above
Step 3: movement rule set
In order to decide on new placements of the target object, the system uses predefined (x, y) coordinates of landmark (static) objects and a set of direction representations.
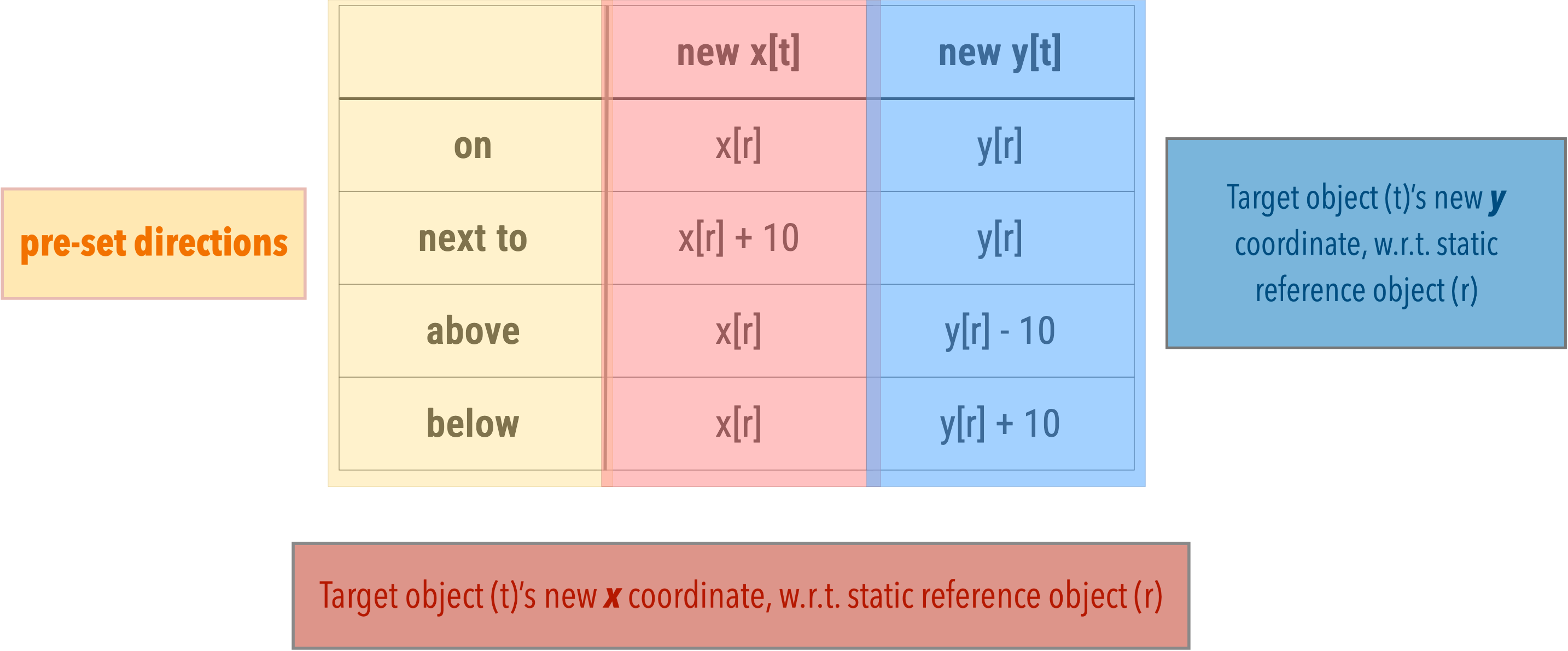
For r referring to the stataic reference object, and t referring to the movable target object.
LLM results
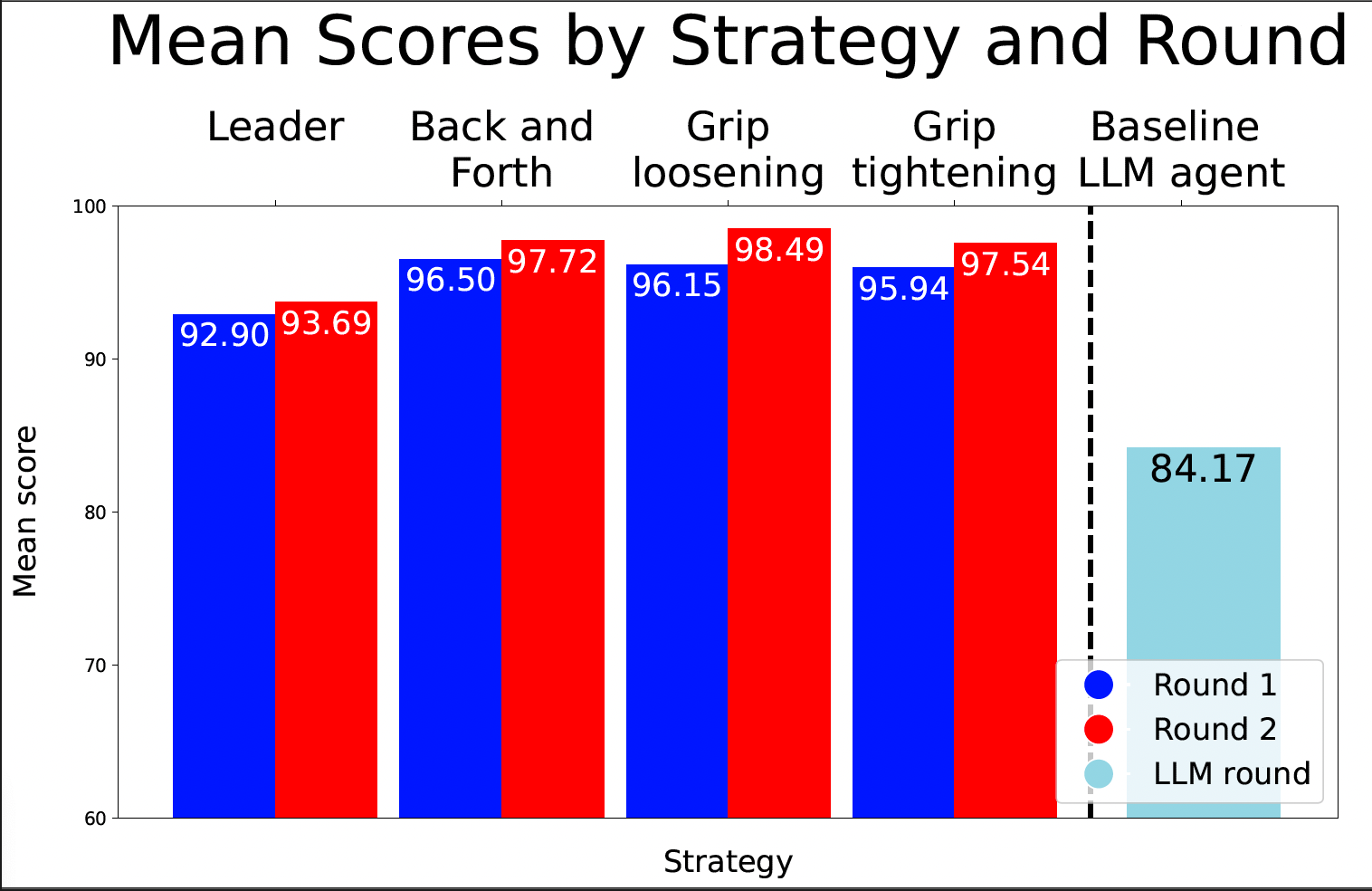
The results of the LLM round indicate that:
- even a simple baseline agent can achieve results close to those of human pairs (see mean score)
- the dominance metric is an effective way of capturing the discrepancy in conversational steering within different strategy groups. Since the LLM agent is forced into an instruction-following role, all the games in this batch will correspond to the leader strategy, which is reflected in the mean dominance score difference shown in the results.
The results can be found below.
Dominance score:
| Strategy | Round 1 | Round 2 |
|---|---|---|
| leader | 1.468 | 2.374 |
| back and forth | 1.17 | 0.981 |
| grip loosening | 1.421 | 0.988 |
| grip tightening | 0.884 | 1.696 |
| LLM | 2.02 | N/A |
References
Schlangen, D., Diekmann, T., Ilinykh, N., & Zarrieß, S. (2018). slurk–a lightweight interaction server for dialogue experiments and data collection. In Proceedings of the 22nd Workshop on the Semantics and Pragmatics of Dialogue (AixDial/semdial 2018).
Götze, J., Paetzel-Prüsmann, M., Liermann, W., Diekmann, T., & Schlangen, D. (2022). The slurk interaction server framework: Better data for better dialog models. In Proceedings of the Thirteenth Language Resources and Evaluation Conference (pp. 4069–4078). Marseille, France: European Language Resources Association.
BibTeX
@inproceedings{jeknic2024dialogue,
title={A Dialogue Game for Eliciting Balanced Collaboration},
author={Isidora Jeknic and David Schlangen and Alexander Koller},
year={2024},
eprint={2406.08202},
archivePrefix={arXiv},
primaryClass={cs.CL},
editor={Tatsuya Kawahara and Vera Demberg and Stefan Ultes and Koji Inoue and Shikib Mehri and David Howcroft and Kazunori Komatani},
booktitle={Proceedings of the 25th Annual Meeting of the Special Interest Group on Discourse and Dialogue},
month={sep},
address={Kyoto, Japan},
publisher={Association for Computational Linguistics},
url={https://aclanthology.org/2024.sigdial-1.41},
doi={10.18653/v1/2024.sigdial-1.41},
pages={477--489},
abstract={Collaboration is an integral part of human dialogue. Typical task-oriented dialogue games assign asymmetric roles to the participants, which limits their ability to elicit naturalistic role-taking in collaboration and its negotiation. We present a novel and simple online setup that favors balanced collaboration: a two-player 2D object placement game in which the players must negotiate the goal state themselves. We show empirically that human players exhibit a variety of role distributions, and that balanced collaboration improves task performance. We also present an LLM-based baseline agent which demonstrates that automatic playing of our game is an interesting challenge for artificial systems.}
}